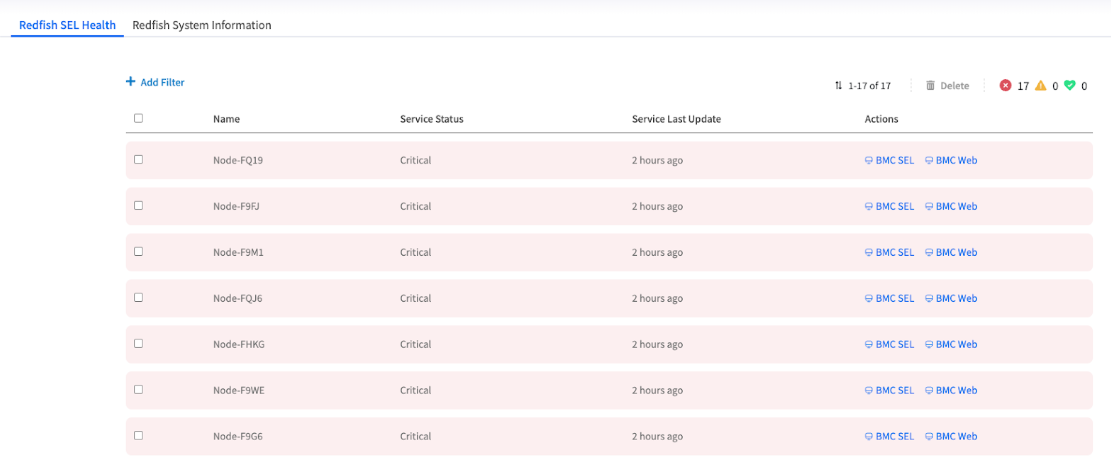
The Redfish SEL Health view showing a list of nodes, with some marked as critical
| Selected Scope | What You See | Example Use Case |
|---|---|---|
| Organization | All nodes from all authorized PODs | Global infrastructure health check across entire organization |
| Hierarchy View | All nodes from PODs within selected HV | Regional data center monitoring (e.g., "East Coast HV" shows POD1, POD2, POD3) |
| POD | All nodes within selected POD | Detailed investigation of specific POD issues |
The Redfish SEL Health view showing a list of nodes, with some marked as critical
| Column | Description & Why It Matters | Diagnostic Value |
|---|---|---|
| Name | Identifier: The unique name of the node. | Node identification |
| Service Status | The Key Indicator: This shows the current health of the selected service on that node (Critical, Good). The entire row is color-coded, so you can spot failing nodes instantly. | PRIMARY - Immediate health status |
| Service Last Update | The "Heartbeat" Timestamp: This shows the last time EDCC successfully received a status update from this service. A stale or old timestamp is a major red flag, indicating a potential network issue or an unresponsive BMC. | CRITICAL - Communication health |
| Actions | Your Investigation Shortcuts: These are dynamic, context-aware links designed to take you directly to the most relevant page for troubleshooting that specific service failure. | TOOLS - Direct investigation paths |
The filter dialog showing the options to filter by Name and Service Status