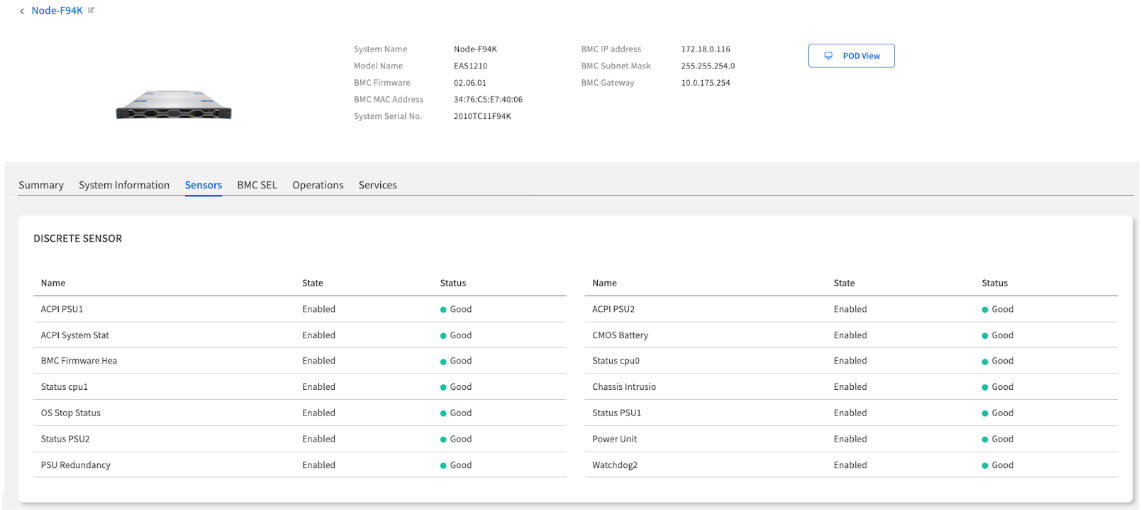
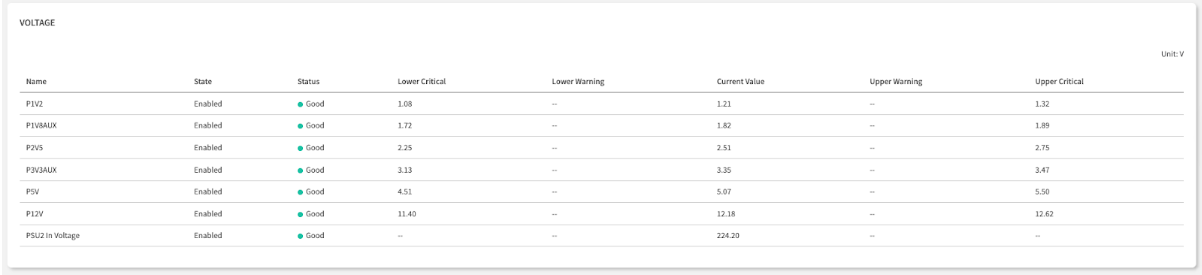
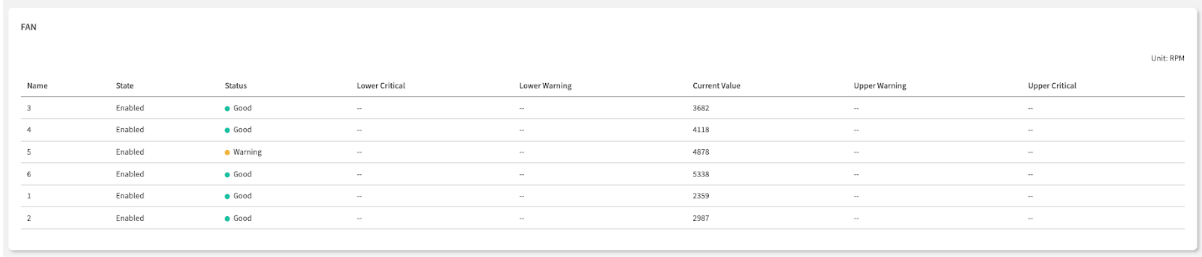
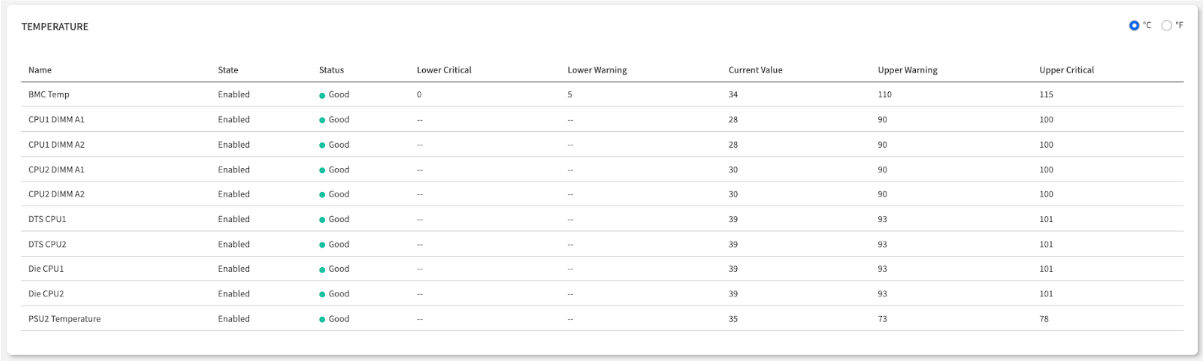
| Status | Your At-a-Glance Health Indicator: Good is normal. Warning or Critical means the sensor has crossed a predefined threshold and requires immediate attention. | First check - prioritize non-green statuses |
| Current Value | The Real-Time Reading: The precise, real-time measurement from the sensor (e.g., Volts, RPM, °C). | Exact measurement - compare against expected ranges |
| Thresholds | The Official Safe Operating Limits: These read-only values are defined by the hardware manufacturer. A Current Value outside these boundaries triggers a Status change. | Reference ranges - understand normal vs. abnormal |